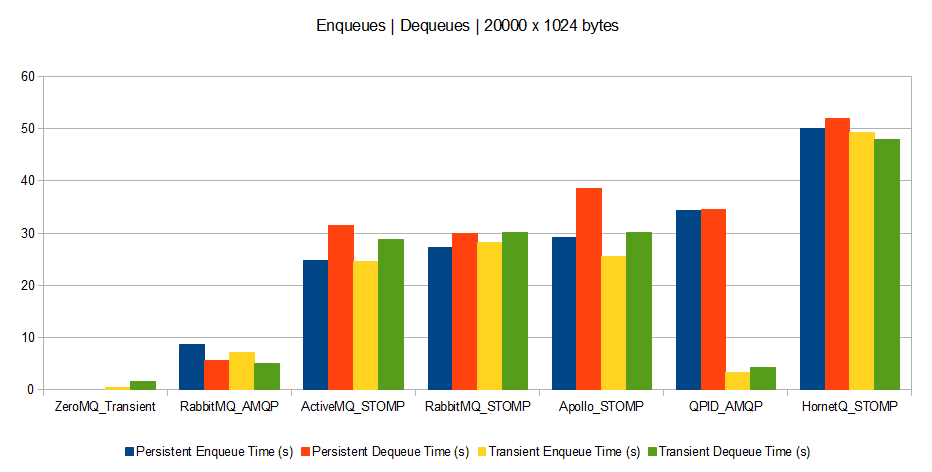
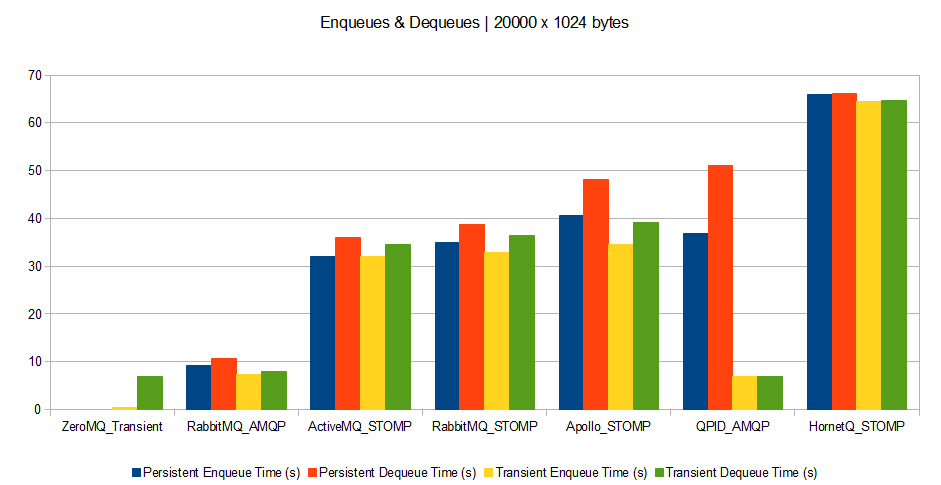
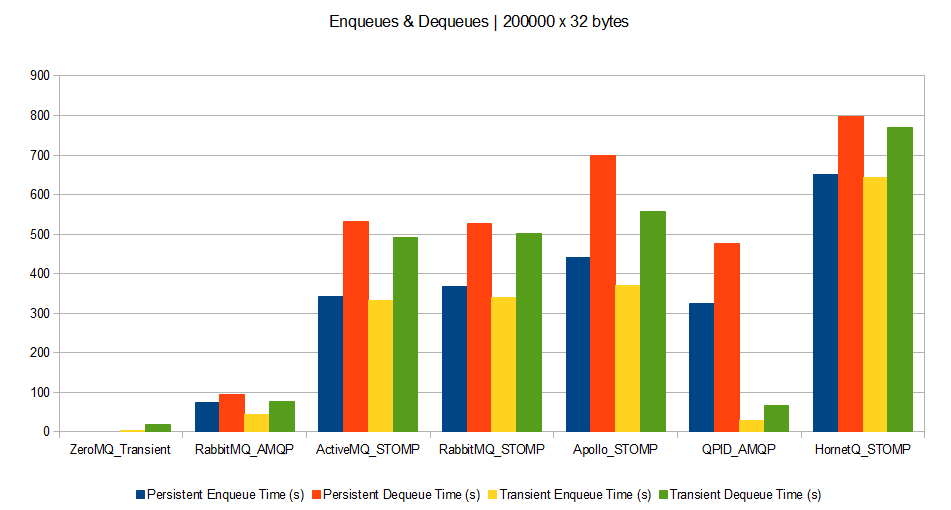
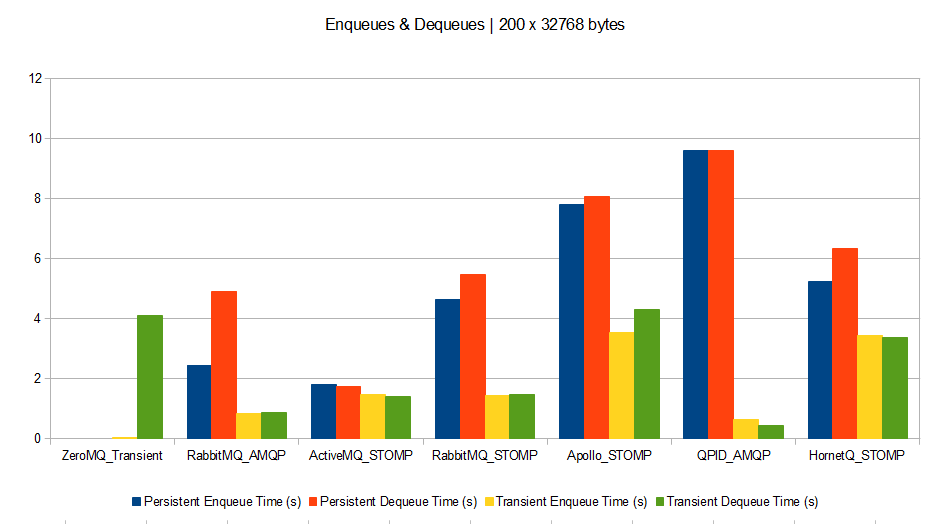
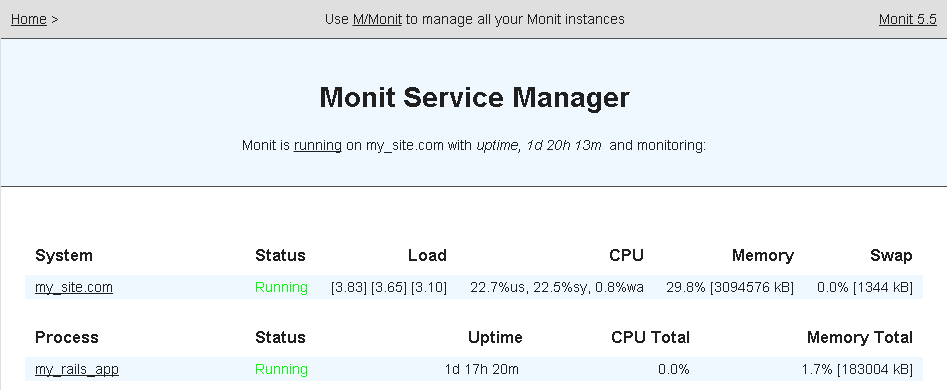
Lately, I received a TF300TG Asus Transformer Pad, shipping with a stock Asus JellyBean (Android 4.1.1) OS.
It is awesome, reactive, playful, efficient, has 3G connectivity with a SIM card slot… but does not have broadband telephony feature!
So I decided to delve into the world of Android unlocking, rooting, and custom ROMs installations to try using it as a phone.
It was a first time for me, and so I decided to share my experience and note all the steps to install custom ROM on Asus TF300TG pad.
- Android architecture
- Unlock the boot-loader
- Install a new boot-loader (aka recovery)
- Root it: grant privileges
- Backup your system
- Install new ROM
Android architecture
First, what are the involved software components in installing custom ROMs on an Android device?
- The boot-loader: it is the first application to be started when switching on the device. It is responsible for system updates and recovery processes. Usually it is locked by vendors: this means that you cannot install another boot-loader without voiding your warranty.
- The Android Kernel: This is a software layer responsible for direct communication with your hardware. Each phone or pad has a Kernel suited to its hardware. Some vendors distribute it, others don’t.
- The Android OS: Android as you know it: a collection of applications, and their different middle-ware layers using the Kernel to work.
This is a broad view of Android architecture, just highlighting the components we will be considering in this post.
All those software components are installed on the device’s internal files system. Installing a new ROM means basically being able to overwrite files of the Android OS and Kernel.
However by default, vendors provide a guarantee on their hardware given that their user can’t modify system files. They enforced this by limiting privileges users have by default on system files (most of them won’t even be able to see those system files). Therefore users need to be granted special privileges to modify system files, and so to install custom ROM.
Basically, acquiring those privileges mean voiding your guarantee on your product.
This post explains all the steps involved in installing ROM on an Android device, focusing on the Asus TF300TG Transformer Pad when needed:
- Unlocking the boot-loader to be able to install a new one
- Installing a new boot-loader, able to modify system files
- Rooting it by installing files that give all privileges
- Backuping the current system, to be able to retrieve it in case of problems
- Installing new ROM on the device
Unlock the boot-loader
Before proceeding, you have to know that unlocking the TF300TG boot-loader simply voids your guarantee.
This being said, Asus itself provides a boot unlocker from their website. It is indexed on the TF300T page, but also works on the TF300TG model.
Download it (should be a file named UnLock_Device_App_V7.apk), and copy it to your tablet’s “Internal storage” as seen when connected to your computer.
Then from your tablet, execute this file (use a files explorer to locate it). You may need to have enabled “Debug mode” and “Install applications from mock locations” in your pad’s settings to execute it. Go through the whole installation process.
Your boot-loader is then unlocked. From now on, when booting your TF300TG, you will see a little message on the upper left corner: “Device is unlocked”
More info here.
Install a new boot-loader (aka recovery)
Once your boot-loader is unlocked, you can install a new one.
There are basically 2 main boot-loader out there:
Personally I would recommend TWRP, as it is far easier to use.
Download the boot-loader of your choice on your computer. It usually fits in a file with extension .blob or .img.
At this point, you will need to have installed Android developer tools on your computer. They include the fastboot tool which we will be using.
Sometimes vendors’ drivers install those tools with their software suite. If not the case, you can always get them by installing the Android SDK, published by Google itself.
Once fastboot is available on your computer, follow those steps to install the new boot-loader:
- Shutdown the pad
- Connect the pad to your computer using its USB cable
- Press the “Volume down” button on the side, along with the Power button on the top, and keep them both pressed until you see something on your screen. You can then release the buttons. This is called booting your pad in Recovery mode.
- Select the USB icon using the “Volume down” button ONLY, and then press the “Volume up” button to select the USB icon once it is highlighted. This makes your device wait for data from the USB connection.
- On your computer, open a command line and get to the directory where you downloaded the new boot-loader (file
.blob or .img).
- Type the command
fastboot -i 0x0B05 flash recovery the-file-name.blob, replacing the-file-name.blob with the name of your downloaded file. This will upload the new boot-loader to your device. If an error occurs, it certainly means that fastboot is not installed correctly, or that your current boot-loader is not unlocked.
- Type the command
fastboot -i 0x0B05 reboot to reboot your device.
You now have a new boot-loader.
More info here.
Root it: grant privileges
Now that we have a new boot-loader, time has come to use it to install a special software package that will grant root privileges.
- Download the rooting package SuperUser from here and copy it to the pad’s “Internal storage”.
- Shutdown your pad and boot it in recovery mode (see previous section).
- Press the “Volume up” button to select the already highlighted RCK icon (not the USB one). This will launch your newly installed Recovery Process.
- In the Recovery Process interface, choose to “Install a zip file from sdcard”, and select the newly copied SuperUser Zip file. Go through the complete installation process.
CWM interface uses the “Volume down” and “Volume up” buttons to navigate, and the Power button to select.
TWRP interface is simply tactile.
Your pad is now rooted.
Backup your system
Once your pad is rooted, I strongly advise that you backup your full system before trying to install any ROM.
- Boot in recovery mode, and launch the Recovery Process (see previous section).
- Navigate to Backup, select the system files, and go through the whole process.
You are now ready to install new ROM!
Install new ROM
ROM can be found in many places over the web. Great resources indexing ROM for a lot of devices are the XDA forums. There you will find all the ROM available for your device.
Be sure that you install a ROM that fits your device! Lots of ROM update the Android Kernel, or rely on specific Kernels. Therefore using a ROM that is fit to another device might crash your Android. If this happens, no panic: you have backed up your system, you can restore it using the Recovery Process (boot in Recovery mode, launch the Recovery Process, then select “Restore” and point it to the backup you made earlier).
Here are the usual steps needed to install a new ROM:
- Download the ROM and copy it to the pad’s “Internal storage” (usually a big Zip file).
- Boot in Recovery mode, and launch the Recovery Process.
- Select “Factory reset” your device. Don’t worry, it will not erase the backups you may have made earlier.
- Select “Install zip from sdcard” and select the zip of your ROM. Go through the complete installation process.
- Select “Wipe” both the “Cache” and the “Dalvik cache”.
- Select “Reboot”.
Usually XDA forums have very complete threads on installing ROMs on devices. I strongly suggest you read them carefully before proceeding.
More info here.
This way I managed to install and test many different ROMs on my Asus TF300TG, a lot of them were rather unstable, and I was always able to get back to my backup went things went wrong.
However … I couldn’t find any that allowed usage of the telephony feature with my SIM card.
Next step is for me to understand how to activate this feature. Will be another post for that.