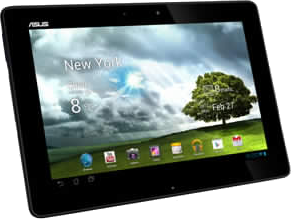
How to install custom ROM on Asus TF300TG Transformer Pad
Lately, I received a TF300TG Asus Transformer Pad, shipping with a stock Asus JellyBean (Android 4.1.1) OS. It is awesome, reactive, playful, efficient, has 3G connectivity with a SIM card slot… but does not have…




