Lately I performed a message queue benchmark, comparing several queuing frameworks (RabbitMQ, ActiveMQ…).
Those benchmarks are part of a complete study conducted by Adina Mihailescu, and everything was presented at the April 2013 riviera.rb meet-up. You should definitely peek into Adina’s great presentation available online right here.
Setup and scenarios
So I wanted to benchmark brokers, using different protocols: I decided to build a little Rails application piloting a binary that was able to enqueue/dequeue items taken from a MySQL database.
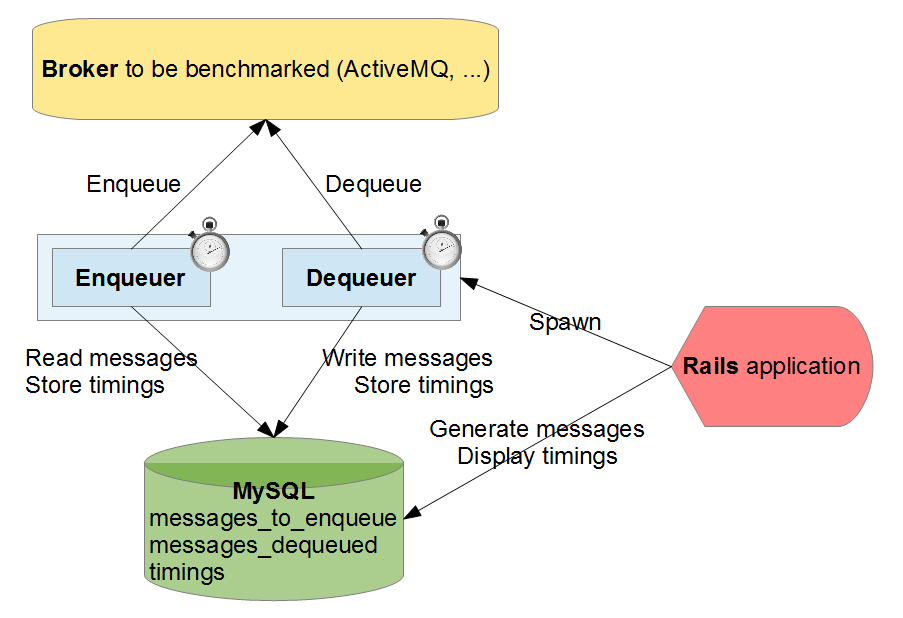
I considered the following scenarios:
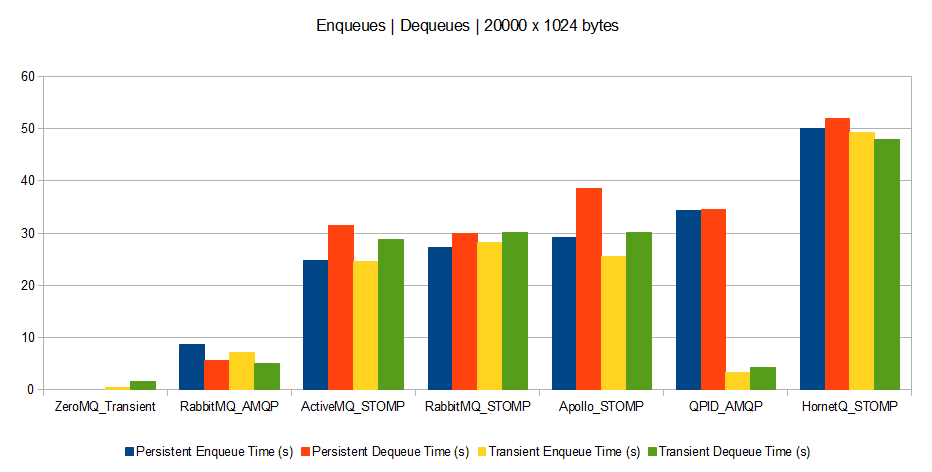
- Scenario A: Enqueuing 20,000 messages of 1024 bytes each, then dequeuing them afterwards.
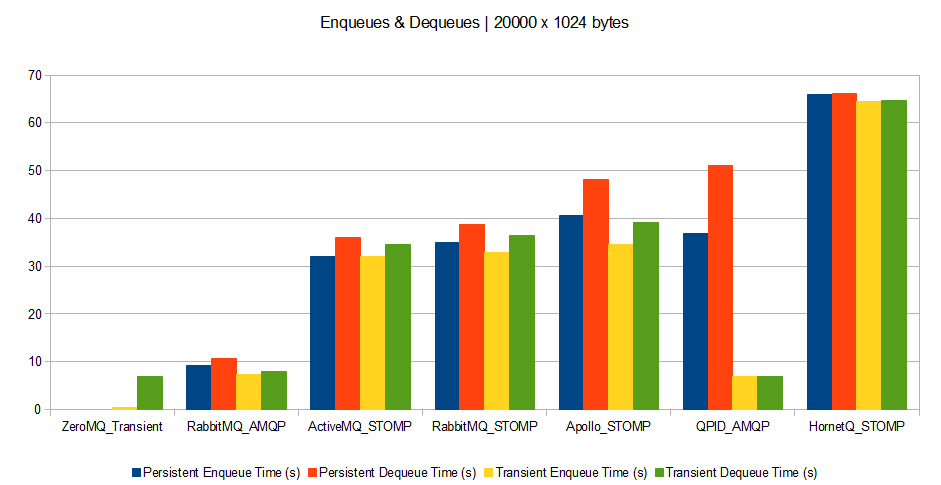
- Scenario B: Enqueuing and dequeuing simultaneously 20,000 messages of 1024 bytes each.
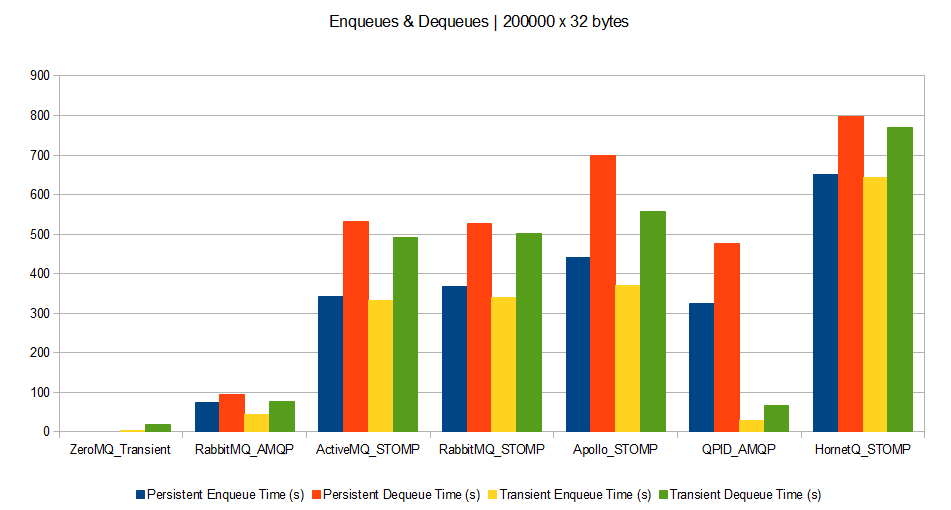
- Scenario C: Enqueuing and dequeuing simultaneously 200,000 messages of 32 bytes each.
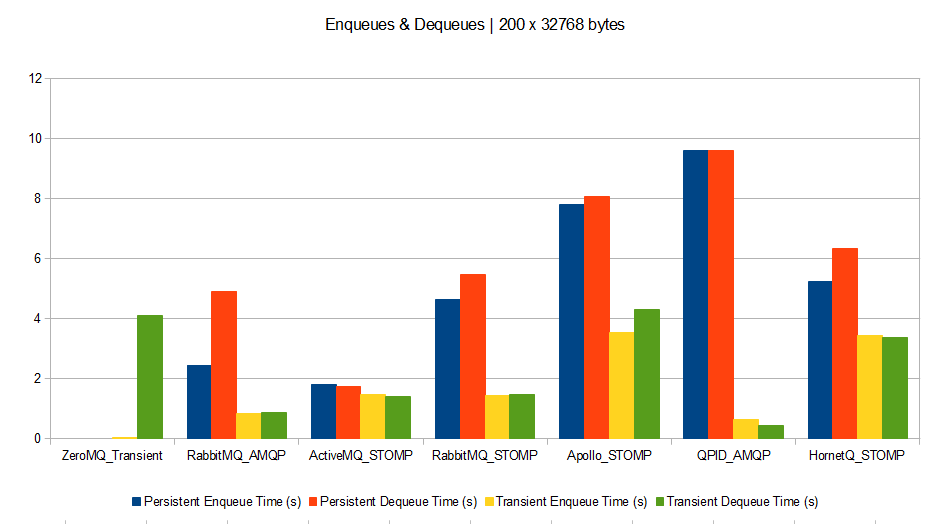
- Scenario D: Enqueuing and dequeuing simultaneously 200 messages of 32768 bytes each.
For each scenario, 1 process is dedicated to enqueuing, and another one is dedicated to dequeuing.
I measured the time spent by each enqueuing and dequeuing process, with 2 different broker configurations:
- Using persistent queues and messages (when the broker is down and back up, queues are still containing items).
- Using transient queues and messages (no persistence: when broker is down, queues and items are lost).
I decided to bench the following brokers:
- ActiveMQ 5.8.0 with STOMP protocol
- RabbitMQ 3.0.2 with STOMP and AMQP protocols
- HornetQ 2.3.0 with STOMP protocol
- Apollo 1.6 with STOMP protocol
- QPID 0.20 (Java broker) with AMQP protocol
- A home-made ZeroMQ 2.2.0 broker, working in memory only (no persistence).
The tests were run on a single laptop with this configuration:
- Model: Dell Studio 1749
- CPU: Intel Core i3 @ 2.40 GHz
- RAM: 4 Gb
- OS: Windows 7 64 bits
- Ruby 1.9.3p392
- Java 1.7.0_17-b02
- Ruby AMQP client gem: amqp 0.9.10
- Ruby STOMP client gem: stomp 1.2.8
- Ruby ZeroMQ gem: ffi-rzmq 1.0.0
Apart from declaring the testing queues in some brokers’ configuration and the persistence settings, all brokers were running with their default configuration out of the box (no tuning made).
You can find all the source code used to perform those benchmarks here on github.
Results
And now, the results (processing time measured in seconds: the lower the better).
Scenario A
Scenario B
Scenario C
Scenario D
Here are the results data sheet for those who are interested: Benchmarks
What can we say about it?
The benchmark setup being simple (just 1 host, using dedicated queues with 1 enqueuer and 1 dequeuer each, no special performance or configuration tuning), the results will just give us a first estimation of performance. More complex scenarios will need more complex setups to draw final thoughts.
However a few trends seem to appear:
- Brokers perform much better with bigger messages. Therefore if your queuing clients can support grouping their messages, this is a win. However grouped messages could not be spread across parallel consumers.
- Persistence drawbacks (disk or db accesses) appear when brokers deal with big messages (except for QPID which is very efficient for transient messages whatever the size). This means that for small and medium messages, time is spent on processing rather than on I/O.
- ZeroMQ broker outperforms all others. This means that unless you have a need for complex broker features, ZeroMQ is a perfect message dispatcher among processes.
- QPID seems to be the best at performing without persistence.
- It seems AMQP protocol is much more optimized than STOMP (at least judging with RabbitMQ’s results). However this might be due to a badly coded Ruby STOMP client, or a badly coded STOMP implementation on RabbitMQ’s side.
- HornetQ seems bad at dealing with small and medium messages, compared to others.
- Except for big messages, RabbitMQ seems to be the best bet as it outperforms others by a factor of 3.
Pingback: Web Tech | Annotary
Pingback: Scott Banwart's Blog › Distributed Weekly 202
Pingback: How Fast is a Rabbit? Basic RabbitMQ Performance Benchmarks | VMware vFabric Blog - VMware Blogs
Pingback: JMS vs RabbitMQ | jraviton
Pingback: How do you permanently delete files from Github, use ansible to modify a file, and other nits ← A Little Ludwig Goes A Long Way
Pingback: 常见开源消息系统 - Web 开发 : 从后端到前端
Pingback: 常见开源消息系统 | 天天三国杀
Pingback: A Quick Messaging Benchmark | snippetjournal
Pingback: How to speedup message passing between computing nodes | CL-UAT
Pingback: Evaluación del nivel y madurez de integración de Message Brokers opensource con WSO2 ESB | Holistic Security and Technology
Pingback: 各种MQ比较-老娘舅