Lately I performed a message queue benchmark, comparing several queuing frameworks (RabbitMQ, ActiveMQ…).
Those benchmarks are part of a complete study conducted by Adina Mihailescu, and everything was presented at the April 2013 riviera.rb meet-up. You should definitely peek into Adina’s great presentation available online right here.
Setup and scenarios
So I wanted to benchmark brokers, using different protocols: I decided to build a little Rails application piloting a binary that was able to enqueue/dequeue items taken from a MySQL database.
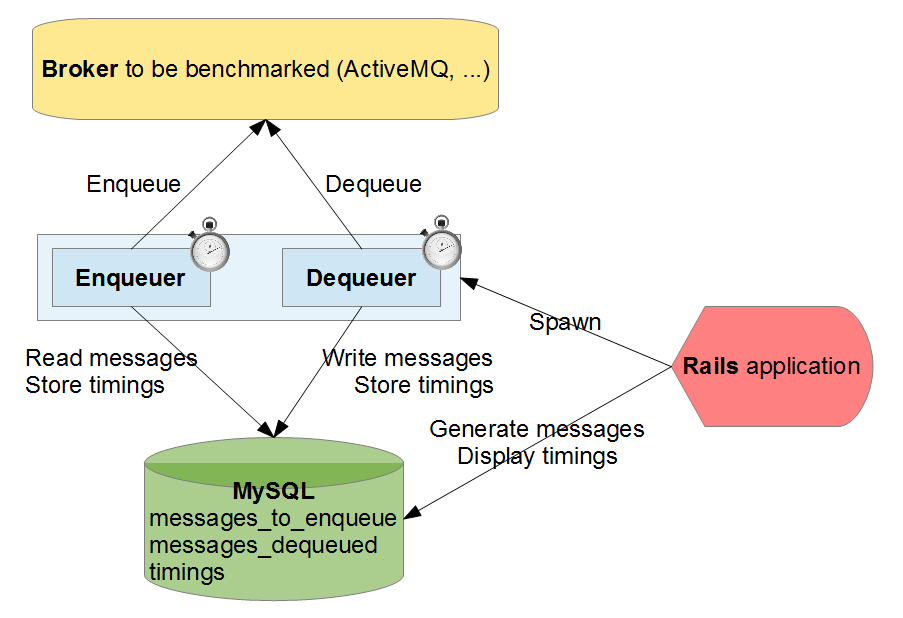
I considered the following scenarios:
- Scenario A: Enqueuing 20,000 messages of 1024 bytes each, then dequeuing them afterwards.
- Scenario B: Enqueuing and dequeuing simultaneously 20,000 messages of 1024 bytes each.
- Scenario C: Enqueuing and dequeuing simultaneously 200,000 messages of 32 bytes each.
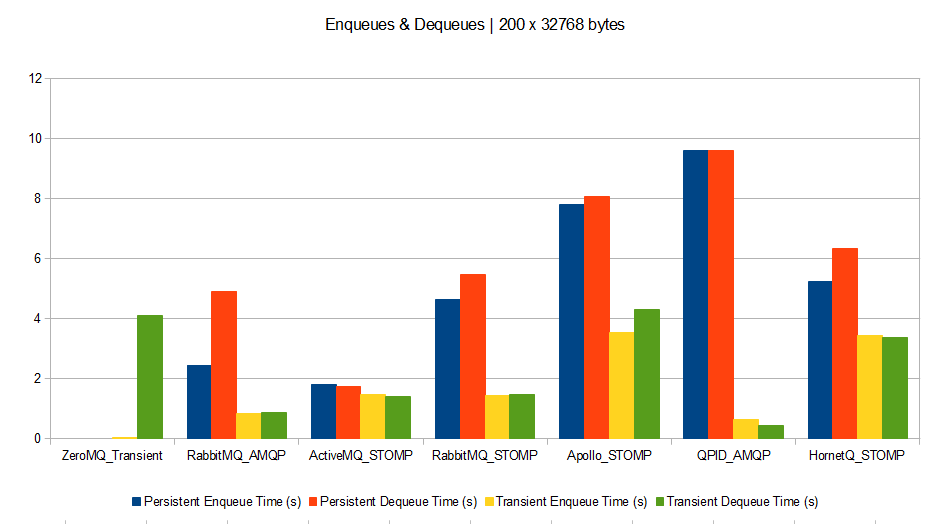
- Scenario D: Enqueuing and dequeuing simultaneously 200 messages of 32768 bytes each.
For each scenario, 1 process is dedicated to enqueuing, and another one is dedicated to dequeuing.
I measured the time spent by each enqueuing and dequeuing process, with 2 different broker configurations:
- Using persistent queues and messages (when the broker is down and back up, queues are still containing items).
- Using transient queues and messages (no persistence: when broker is down, queues and items are lost).
I decided to bench the following brokers:
- ActiveMQ 5.8.0 with STOMP protocol
- RabbitMQ 3.0.2 with STOMP and AMQP protocols
- HornetQ 2.3.0 with STOMP protocol
- Apollo 1.6 with STOMP protocol
- QPID 0.20 (Java broker) with AMQP protocol
- A home-made ZeroMQ 2.2.0 broker, working in memory only (no persistence).
The tests were run on a single laptop with this configuration:
- Model: Dell Studio 1749
- CPU: Intel Core i3 @ 2.40 GHz
- RAM: 4 Gb
- OS: Windows 7 64 bits
- Ruby 1.9.3p392
- Java 1.7.0_17-b02
- Ruby AMQP client gem: amqp 0.9.10
- Ruby STOMP client gem: stomp 1.2.8
- Ruby ZeroMQ gem: ffi-rzmq 1.0.0
Apart from declaring the testing queues in some brokers’ configuration and the persistence settings, all brokers were running with their default configuration out of the box (no tuning made).
You can find all the source code used to perform those benchmarks here on github.
Results
And now, the results (processing time measured in seconds: the lower the better).
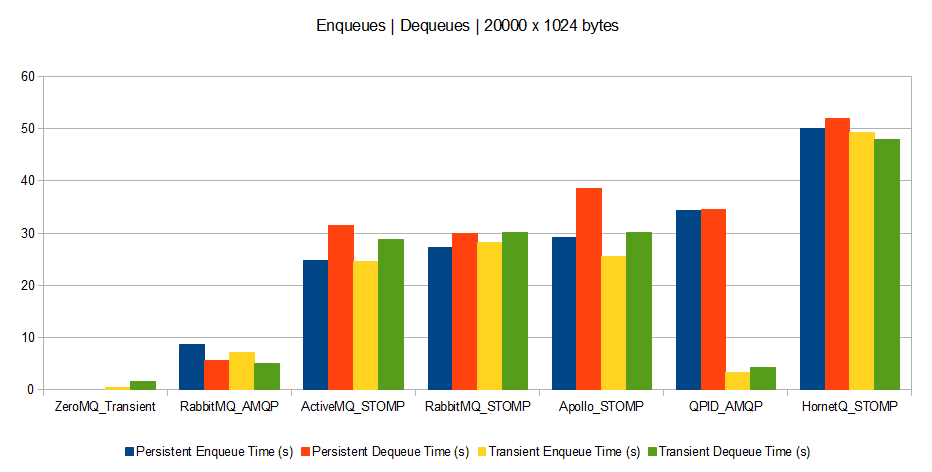
Scenario A
Scenario B
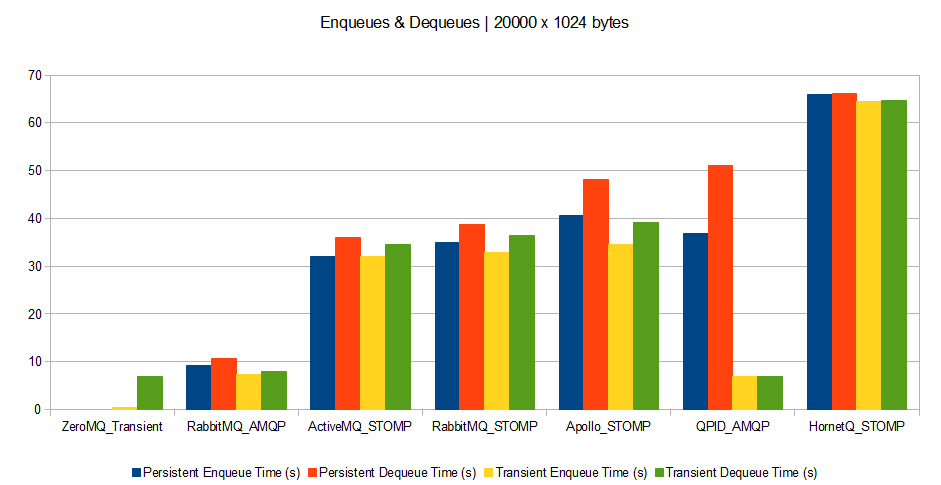
Scenario C
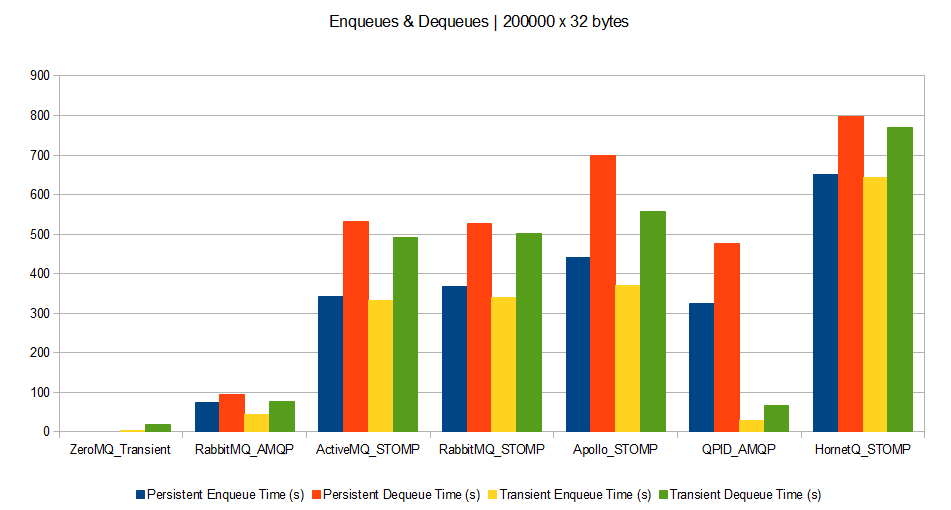
Scenario D
Here are the results data sheet for those who are interested: Benchmarks
What can we say about it?
The benchmark setup being simple (just 1 host, using dedicated queues with 1 enqueuer and 1 dequeuer each, no special performance or configuration tuning), the results will just give us a first estimation of performance. More complex scenarios will need more complex setups to draw final thoughts.
However a few trends seem to appear:
- Brokers perform much better with bigger messages. Therefore if your queuing clients can support grouping their messages, this is a win. However grouped messages could not be spread across parallel consumers.
- Persistence drawbacks (disk or db accesses) appear when brokers deal with big messages (except for QPID which is very efficient for transient messages whatever the size). This means that for small and medium messages, time is spent on processing rather than on I/O.
- ZeroMQ broker outperforms all others. This means that unless you have a need for complex broker features, ZeroMQ is a perfect message dispatcher among processes.
- QPID seems to be the best at performing without persistence.
- It seems AMQP protocol is much more optimized than STOMP (at least judging with RabbitMQ’s results). However this might be due to a badly coded Ruby STOMP client, or a badly coded STOMP implementation on RabbitMQ’s side.
- HornetQ seems bad at dealing with small and medium messages, compared to others.
- Except for big messages, RabbitMQ seems to be the best bet as it outperforms others by a factor of 3.
Thank you very much, this is bookmarked and stored for refenrence! 😉
Thanks! Glad it helped.
Pingback: Web Tech | Annotary
Good overview, did you have time to do any more complex queuing or any message transformations? I’d really like to see how everything compares when parsing the messages.
Thanks.
Unfortunately I did not have time to delve further into it. However source code can be easily forked, and playing with it should not be difficult.
If I happen to complete my tests with other brokers or more complex scenarios, I will update it.
Good overview, did you have a chance to try more complex setups or message transformations? I would be interested to see how these compare in more realistic scenarios.
A comment more on the presentation: please do not re-order the x-axis of the graphs. I understand that you are re-ordering them based on performance, but this requires me to re-read (and process) the x-axis every time, and also stops me from quickly visually comparing graphs.
A more standard way is to keep to a single ordering to the entries of the x-axis, and allow the graph speak for itself…
Constructively 🙂
Thanks for your comment and point taken 🙂
You’re right, and I just updated the graphs to reflect it.
Just out of interest … which persistent store did you used with Qpid Java broker? I assume DerbyDB is the one which would be considered more out of the box, correct? BDB might give you better persistent performance … at least in our tests it did …
Regards
Jakub
Indeed, it is DerbyDB.
I think that tuning some brokers might have given better results. To be done in a later benchmark!
Smurf pants/year?
Damn man, I didn’t know that ZeroMQ could push out so many smurf pants. Compared to the 60 smurf pants/year of Hornet ZeroMQ is just killing it. I am assuming that y=smurf pants and the time scale is per-year right? Totally makes sense.
The y axis is the total enqueue or dequeue time, expressed in seconds.
The number of messages and their size are indicated on each title, and changes with the scenario.
So that means for scenario A that HornetQ took 60 seconds to dequeue 20000 messages of 1024 bytes each, compared to ZeroMQ that took only 8 seconds for the same operation.
Hope it gets clearer
Pingback: Scott Banwart's Blog › Distributed Weekly 202
Is there any reason you choose the Java Qpid instead of C++ or both ?
Could you please run the measurement also for the C++ Qpid ? It’ll be interesting to compare both implementations.
The main reason is that compiling the C++ broker was a PITA on Win7 without VisualStudio being installed.
I agree this is kind of a shameful reason, but I was hoping the Java version to be efficient enough.
This is definitely something to cover if I happen to delve further into those benchmarks. I will update it if I do it.
If you used the same programming language for implementing the messages queues, it would be fair. But Java, Python, Ruby etc. implementation are always going to be slower than implementations in C. Plus there is a HUGE difference between in-memory messages-queues and persisted queues. These are two different types of message-queue implementations. The benchmarks should respect that.
I’m not affiliated with any of these. I’d bet on ZeroMQ if I had to, but I believe there are unknown queing algorithms, that perform better than all of these.
Each broker has its own implementation, and the goal of this benchmark wasn’t to compare languages efficiency, but rather brokers’ efficiency. If a broker chooses to use Java or C to answer to a problem, it is his choice, not mine. A good Java code can perform much faster than a bad C code, and all the tests on the client side were performed using Ruby clients, so the comparison is valid.
Those benchmarks respect persistent and transient implementations. Look at the charts.
Pingback: How Fast is a Rabbit? Basic RabbitMQ Performance Benchmarks | VMware vFabric Blog - VMware Blogs
Thanks for this interesting benchmark, I’ll probably look into RabbitMQ as I need persistence.
What about CPU and RAM consumption during your tests ?
I did not record CPU and RAM consumption, but as far as I remember each broker was taking around 300Mb after having items enqueued (except some Java ones that were using 1Gb because they were started using -Xms1024m JVM option by default). CPU consumption was pretty reasonable (around 50%) and the system did not get hung in any way. Even disk IO were running smoothly.
Glad it helped!
in my case I want to know if those queue are configured to be clustered and support database persistence against fail-over.
your writing is based on the simple queue, right?
and the persist queue is use to file-system for recovery.
Let me ask,
how do you expected which queue is the quickest one if you are configured according to my case?
thanks in advance.
You are right: our tests were covering only simple queues, and persistence was achieved using disk or database.
However I asked Adina (who conducted the study) about the features you are asking for, and here is her reply:
So those brokers can be configured this way, but you will need to conduct benchmarks adapted to your specific use-case to draw correct conclusions. If you happen to do so, don’t hesitate to share them, I will be interested too!
Thanks for doing the analysis here; it’s great to have some data from which to draw conclusions. But I’m looking at ActiveMQ and RabbitMQ (which come out very similar in most of your tests), and I think you’re missing a few conclusions about that comparison. Here’s what it looks like to me; are these wrong?
1. RabbitMQ and ActiveMQ perform about equivalently on STOMP for small and medium messages, and for large non-persistent messages.
2. However, RabbitMQ performs markedly worse than ActiveMQ for large persistent messages.
3. Although you say that RabbitMQ seems to be the best except for large messages, #1 and #2 probably mean that either ActiveMQ or RabbitMQ would perform equivalently (not that RabbitMQ would be better) except for large persistent messages, and that either of them would be better than the other options.
4. Although you say RabbitMQ “outperforms others by a factor of 3”, this is only true of some of the others, so the statement’s a bit misleading.
You’re right on all points: ActiveMQ performs better than RabbitMQ for large persistent messages only.
I would say that RabbitMQ outperforms most of the others by a factor of at least 3 for most of the use cases.
Thanks for your precisions!
Pingback: JMS vs RabbitMQ | jraviton
Most of the problems today will require clustering. Benchmarking against a single node is unfair, ZeroMQ or HornetQ won’t show all their potential.
At the same time the timing for HornetQ is _very_ suspicious. How have you configured each of the Brokers? This looks like you persisted HornetQ with a database behind, and that’s not the typical configuration and of course not the kind of configuration that can should be compared with RabbitMQ unless you want to compare pears and apples.
Each broker was used using its default configuration.
I only made sure they used transient messages (no on-disk databases, just in memory) for the tests requiring transient messages. For non-transient messages, I used their default engine.
So don’t worry, I didn’t compare pears and apples 😉
This being said, HornetQ performance seems to be highly dependent on the protocol used, and it seems that HornetQ’s STOMP implementation suffers from performance problems. That’s why I made sure to specify which protocols have been used to not compare pears and apples once again.
You don’t cluster, and therefor don’t represent a real scenario at all.
You compare default configurations and you are not comparing pears and apples? Think about that.
You don’t publish the configuration of the different brokers.
You measure timing and not throughput. What if QPid performs with high latency but very high throughput.
The Standard Performance Evaluation Corporation, tested HornetQ (and others in a scientifically fair comparison) and it performed 8.2 Millions messages per second, in a single 2 chip 4 core CPU with 24576 MB of memory and a 1 GbE network interface.
One of your winners, RabbitMQ will rarely do more that 80k messages per second following their own benchmark. That’s 0.08 Millions versus 8.2 millions.
Please, stop confusing people. This is not a fair comparison.
Thanks for the links to other benchmarks, very interesting too.
It is normal to have different results based on different setups. there is no 1 solution for all problems and there is no “best” absolute queuing framework (this is the point in having many different frameworks).
It all depends on the setup and the traffic you send in.
My setup is much more simpler than the ones you refer to, and I don’t claim that my results scale to other setups. As I wrote: “More complex scenarios will need more complex setups to draw final thoughts.”
I tried to not confuse people by clearly framing the setup of my tests and guarding against drawing absolute conclusions based on this simple setup.
You talk alot about comparing pears and apples, but you’ve just compared a benchmark made using a dedicated blade for the server and other 4 dedicated blades for the clients on the HornetQ side, while RabbitMQ were made using a single blade, running both the server and the client.
Please don’t blame the OP for your own lack of attention. As he said enough times, these results reflects how well the MQs act on his setup, and surely will differ, as you have tons of indirect variables that impact on each (OS, arch, technology support like VT-X/VT-D/AMD-V, memory type, bus, libs, etcetera).
Pingback: How do you permanently delete files from Github, use ansible to modify a file, and other nits ← A Little Ludwig Goes A Long Way
Pingback: 常见开源消息系统 - Web 开发 : 从后端到前端
Pingback: 常见开源消息系统 | 天天三国杀
Hi Muriel, would it be possible for you to add Hazelcast to this benchmark or if your source material for this benchmark is available I could also do the test with Hazelcast included
Hi Josiah
I guess once you have a Hazelcast installation running, it might not be difficult to integrate it to the benchmarks.
Feel free to fork and play with the benchmark source code here.
To add a new engine, create a new file in the queue_tester/lib/queue_tester/engines directory (see other files in there) and implement the enqueue/dequeue/flush methods.
You might want to use the hazelcast-client Ruby gem to use Hazelcast from Ruby.
Once you have it running, don’t hesitate to issue a pull request !
Cheers
Muriel
It’s not fair to test messaging performance on a windows laptop without tuning the platform. These brokers are extremely flexible when it comes to persistence, the defaults are far from optimized.
Windows is well known for poor file persistence performance. There are native I/O libraries that Red Hat ships with HornetQ and ActiveMQ that greatly improve the persistence performance. HornetQ can leverage Asynchronous IO [1] using the libaio package in Linux for better performance. ActiveMQ can persist to the file system using LevelDB [2] which offers superior performance as well.
[1] https://access.redhat.com/site/documentation/en-US/JBoss_Enterprise_Application_Platform/6.1/html-single/Administration_and_Configuration_Guide/index.html#About_Persistence_in_HornetQ
[2] http://activemq.apache.org/leveldb-store.html
Thanks a lot for all the pointers and advices you give to fine tune their performance, really helpful!
As said earlier, each setup is unique, and one should thoroughly test and tune each solution given its environmental constraints before choosing its winner.
Those were my environmental constraints (hardware, OS and language related) and those results are far from being definitive.
Cheers
Did you try running ActiveMQ with the AMQP implementation that was added in 5.8.0? It would be interesting to see the comparison with RabbitMQ.
Unfortunately I couldn’t at the time of the article’s writing, as the only Ruby AMQP client library I could find was incompatible with AMQP 1.0 (supported only AMQP 0.9).
So I had to stick with brokers offering support for AMQP 0.9, which is not ActiveMQ’s case.
Hi
I didn’t understand how it was determined that RabbitMQ outperforms all, when the tests are showing zeroMQ is faster at most tests
Am I missing something ?
Hi
The simple ZeroMQ implementation I wrote cannot be considered as a complete queuing framework: it does not handle persistence, and is really not bullet-proof at all.
The point in including it in this bench was to realize how ZeroMQ compares when one just need to send some messages without persistence in simple setups. And indeed, if you don’t need complex queuing mechanisms or persistence, ZeroMQ is the best choice.
It would be interesting though to have a complete queuing framework using ZeroMQ as its transport layer, and compare it with the others, but I did not find it at the time.
Pingback: A Quick Messaging Benchmark | snippetjournal
Hi,
very interesting benchmark. It’s simple to understand and shows basic comparison of these frameworks. It was really helpful for me.
Next time you perform a benchmark, try including the Wsp Distributed Pub/Sub System which is in production in Bing. You can find it at http://pubsub.codeplex.com/.
Yep, looks promising!
Thanks for the link.
Comparing a binary protocol like AMQP against Stomp which is HTTP based is not fair either.
On ActiveMQ for example you got OpenWire, which is binary and outperforms Stomp.
Each broker makes its own choices in terms of protocols, and for some use cases STOMP outperformed AMQP.
Too bad I could not find a Ruby implementation of OpenWire at the time of this benchmark. I would have added it.
Thanks for your efforts
You’re welcome
A related comparison of performance of replicated message queues can be found here: http://www.warski.org/blog/2014/07/evaluating-persistent-replicated-message-queues/ (includes RabbitMQ, HornetQ, Kafka, SQS and Mongo)
Thanks for your input!
We can clearly see the advantages of other queues like HornetQ in such setups.
Pingback: How to speedup message passing between computing nodes | CL-UAT
Pingback: Evaluación del nivel y madurez de integración de Message Brokers opensource con WSO2 ESB | Holistic Security and Technology
Thanks Muriel,
It’s a very good job.
It’s also very important for me to have such benchmark.
I’m a Java EE developer and used to work with JMS: OpenMQ (Glassfish) and HornetQ (JBoss) for small and medium messages. However your benchmark shows that HornetQ seems bad for that.
Is there a chance to have a bench with OpenMQ among these brokers. It would be nice to have it.
Thanks again for your post.
Thanks 😀
It is unlikely that I will get time soon to delve deeper into this benchmark, but if it happens I will make sure to include OpenMQ for sure.
So many frameworks and usecases to be tested 😀
Would be very interesting to also include apache Kafka in these results
Pingback: 各种MQ比较-老娘舅